7 Trillion Passwords Couldn't Crack This Bitcoin Wallet.
AI Did It in Minutes.
How contextual intelligence beat brute force — and what it means for business.

Last week, a developer known as @cprkrn on X recovered 5 Bitcoin from a wallet that had been locked for 11 years. That's roughly $400,000 sitting behind a password he'd forgotten since college.
He'd tried everything. Professional recovery services. Brute-force tools like Hashcat and btcrecover. An estimated 7 trillion password combinations. None of it worked.
Professional Recovery
Paid services, ~$250 spent
Hashcat / btcrecover
Billions of brute-force attempts
7 Trillion Combinations
Estimated total password guesses
Then he uploaded his entire old college computer — files, documents, notes, everything — into Claude. And Claude cracked it.
Not by trying more passwords. By doing what no brute-force tool can: connecting context across disparate files to find an older wallet file and a bug in the recovery software itself.
How Claude cracked it:
- 1Analyzed the full contents of an old college computer — files, documents, notes
- 2Identified an older
wallet.datfile that predated the password change - 3Found a bug in
btcrecoverthat was incorrectly concatenating a shared key with the password - 4Combined the mnemonic phrase with the older wallet file to recover access
The Pattern: Better Retrieval Beats More Compute

This story isn't just a cool crypto recovery. It's a demonstration of something the AI research community is quantifying right now.
On the same day, Exa.ai published research comparing their semantic search engine against standard SERP (Google proxy) as the backend for RL-trained agents. The results were definitive.
| Benchmark | 4B + Exa | 4B + SERP | 235B Base |
|---|---|---|---|
| SimpleQA | 0.767 | 0.692 | 0.730 |
| 2WikiMultihopQA | 0.839 | 0.798 | 0.774 |
| HotpotQA | 0.694 | 0.684 | 0.632 |
| FRAMES | 0.566 | 0.521 | 0.604 |
| MuSiQue | 0.311 | 0.307 | 0.273 |
Three patterns stand out from the data:
Higher Performance
Exa-trained agents outperform SERP-trained agents on pass@k across all values of k. Every benchmark, every sampling budget.
More Compute Efficient
Training with Exa required 69% fewer tokens to match SERP performance. 62% fewer search calls. 58% fewer turns.
Smaller Model Wins
A 4B model with Exa often exceeds a 235B base model. Better search compensates for 60× fewer parameters.
The pattern is the same in both the Bitcoin story and the Exa research: contextual intelligence destroys brute force. More passwords, more parameters, more compute — none of it matters if you're looking in the wrong places. What matters is finding the right information and connecting it correctly.
Cross-Backend Transfer
Exa's research also tested what happens when you swap search backends at inference time:
- → Agents trained on Exa perform better regardless of which search engine they use at inference
- → Using Exa at inference improves performance for both trained agents — even the SERP-trained one
- → Exa returns relevant answers 10.7% more often per search call — denser reward signal compounds over training
This means models trained on better search don't just perform better — they learn better search strategies that transfer to any backend.
Why This Matters for Business
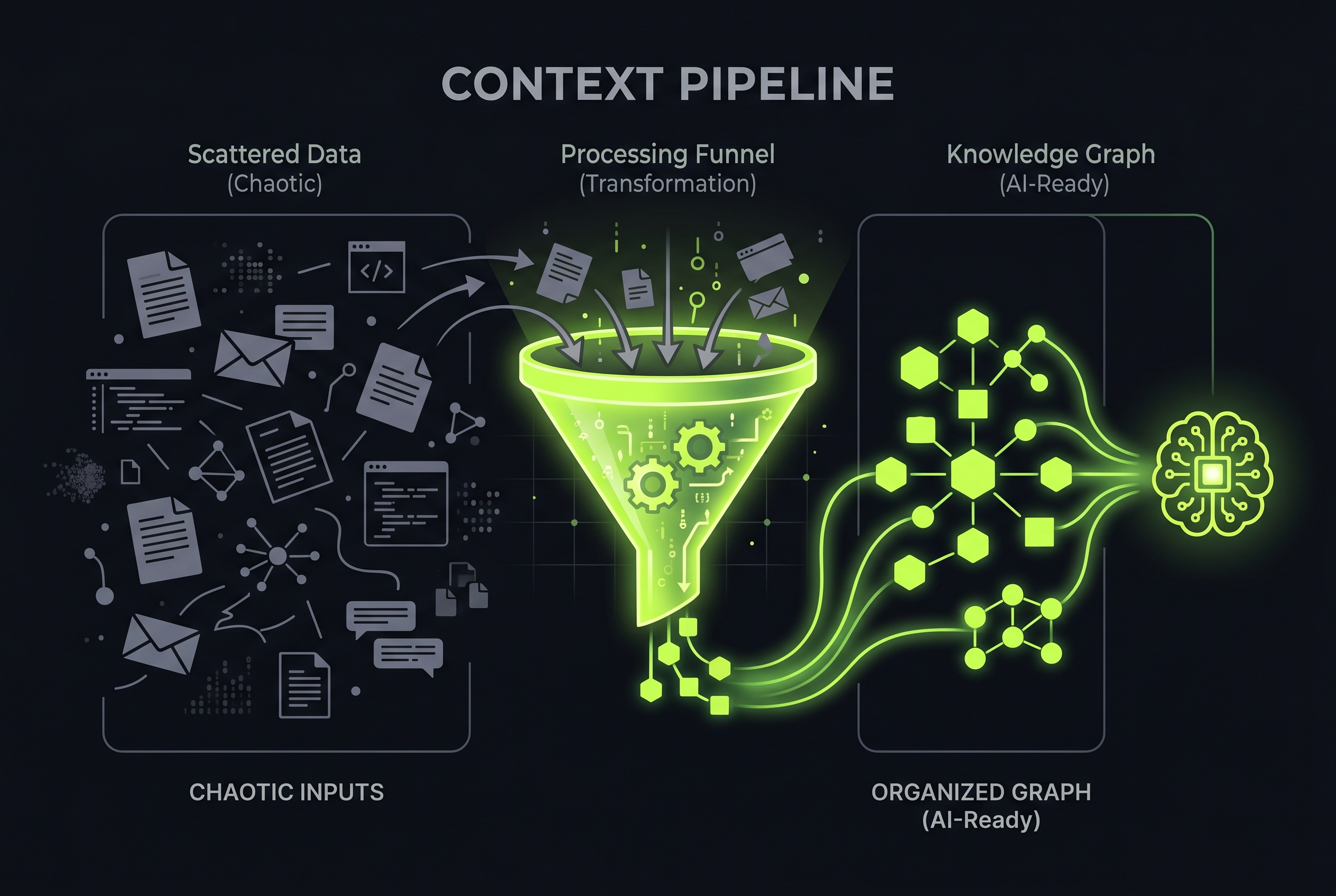
Most businesses approach AI like a brute-force password cracker: throw more data at it, try more prompts, run more iterations. It's the equivalent of trying 7 trillion combinations and hoping one works.
The smarter approach — the one that actually delivers results — is giving AI the right context at the right time. Full business context. Connected data. Semantic understanding of what matters and what doesn't.
Brute Force Approach
What Most Businesses Do
- ✗Throw more data at the problem
- ✗Try more prompts, run more iterations
- ✗Buy bigger models, spend more on compute
- ✗Reactive — wait for AI to hallucinate, then correct
Context-First Approach
What Actually Works
- ✓Curate and connect the right data
- ✓Build semantic search into the pipeline
- ✓Smaller model + better context = better results
- ✓Proactive — AI finds the right answer, not more answers
That's how @cprkrn recovered $400K. That's how Exa's 4B model beat a 235B model. And that's how businesses should be thinking about AI implementation: not "how much compute can I throw at this," but "how good is the context I'm giving my AI?"
The Takeaway
The moat isn't the model. It's the retrieval.
- → Better search → better agents → better outcomes
- → Contextual reasoning > computational brute force
- → A small model with great context beats a large model with poor context
- → 7 trillion guesses got nothing on one good connection
For businesses investing in AI, this means your priority shouldn't be buying the biggest model. It should be building the best context pipeline — connecting your data, your documents, your institutional knowledge into something your AI can actually reason over.
The @cprkrn story proves it at the individual level: one person, one AI, one breakthrough — not from more compute, but from better context. The Exa research proves it at scale: across every benchmark tested, better retrieval beats bigger models.
Because 7 trillion guesses got nothing on one good connection.
Want AI that actually works?
I build AI-accelerated systems that research, execute, and scale — with security-first methodology.
Let's talk →